1、算法介绍
relevance score(相关性分数) 算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度。Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法。TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)
1.1 Term frequency
搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关。

数学公司并不重要,看下面例子就清楚了
搜索请求:阿莫西林
doc1:阿莫西林胶囊是什么。。。阿莫西林胶囊能做什么。。。。阿莫西林胶囊结构
doc2:本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
很容易发现对于阿莫西林关键词来说在doc1中出现的次数大于doc2的,所以doc1的优先级高于doc2
1.2 Inverse document frequency
搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关.
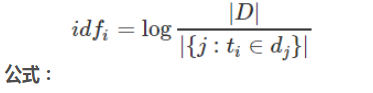

首先看下面内容
搜索请求:阿莫西林胶囊
doc1:A市健康大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc2:B市民生大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc3:C市未来大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
可以看到,对于关键词阿莫西林来说,所有的doc里面都包含这个关键词,那说明这个关键词不是那么重要,说明这个关键词所占的权重很低。再看下面内容
搜索请求:A市 阿莫西林胶囊
doc1:A市健康大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc2:B市民生大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc3:C市未来大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
再加上A市这个关键词,这样的话只有doc1里面才存在,这样的话权重才高,所以可以得出结论:整个索引库中出现的词的频率越小,那么相关度权重越高。
1.3 Field-length norm
除了上面两个因素影响相关度评分的计算之外,还有一个就是字段长度也会影响评分的计算。具体来说就是,field的长度越长,相关度越弱
搜索请求:A市 阿莫西林胶囊
doc1:{"title":"A市健康大药房简介。","content":"本药店有、红霉素胶囊、青霉素胶囊。。。(一万字)"}
doc2:{"title":"B市民生大药房简介。","content":"本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。(一万字)"}
两个文档均只有一个字段被命中。为啥doc1>doc2,因为title字段的长度小于content的字段,几个字就命中相比于一万字才命中,当然几个字就命中的排在前面
2、 _score是如何被计算出来的
步骤如下:
1、 对用户输入的关键词分词;
2、 每个分词分别计算对每个匹配文档的TF和IDF值;
3、 综合每个分词的TF/IDF值,利用公式计算每个文档总分;
4、 最后按照score降序返回;
可以举个例子来看一下。这里使用explain关键字来解释排序的过程。
首先创建索引
PUT /book/
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"studymodel": {
"type": "keyword"
},
"price": {
"type": "double"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"pic": {
"type": "text",
"index": false
}
}
}
}
接着添加测试数据
PUT /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是一个非常流行的开发框架。此开发框架可以帮助不擅长css页面开发的程序人员轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price": 38.6,
"timestamp": "2019-08-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"bootstrap",
"dev"
]
}
PUT /book/_doc/2
{
"name": "java编程思想",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price": 68.6,
"timestamp": "2019-08-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"java",
"dev"
]
}
PUT /book/_doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price": 88.6,
"timestamp": "2019-08-24 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"spring",
"java"
]
}
然后在使用如下命令查看_score的计算
GET /book/_search?explain=true
{
"query": {
"match": {
"description": "java程序员"
}
}
}
返回的内容太多,这里只展示第一条的数据的内容
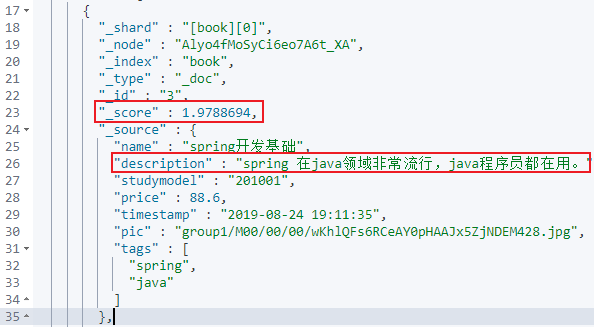
查看代码
{
"_shard" : "[book][0]",
"_node" : "Alyo4fMoSyCi6eo7A6t_XA",
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.9788694,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
},
"_explanation" : {
"value" : 1.9788694,
"description" : "sum of:",
"details" : [
{
"value" : 0.7502767,
"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7502767,
"description" : "score(freq=2.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.7256004,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 2.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 23.666666,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 1.2285928,
"description" : "weight(description:程序员 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 1.2285928,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.98082924,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.56936646,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 23.666666,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
},
对于上面的返回结果,我们先看第一部分,首先就是返回的数据
接着就是对评分计算的解释,按照上面给出的4个步骤分析,首先对关键词分词,这里分为了java 程序员两个关键词,先来看看java关键词的解释
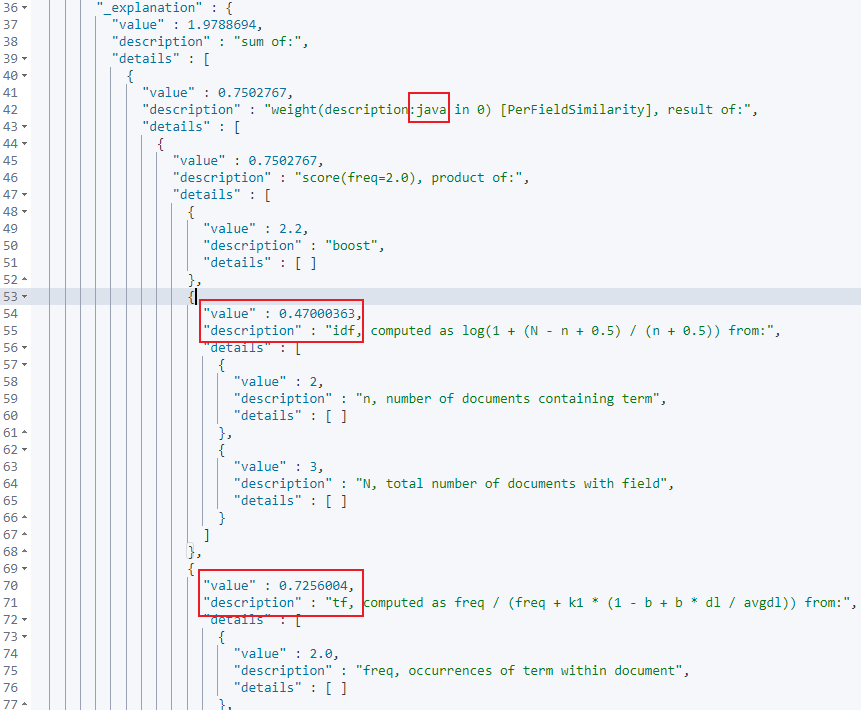
可以看到计算java关键词的tf,idf的值,同理在下方也能看到计算程序员关键词的tf,idf的值。
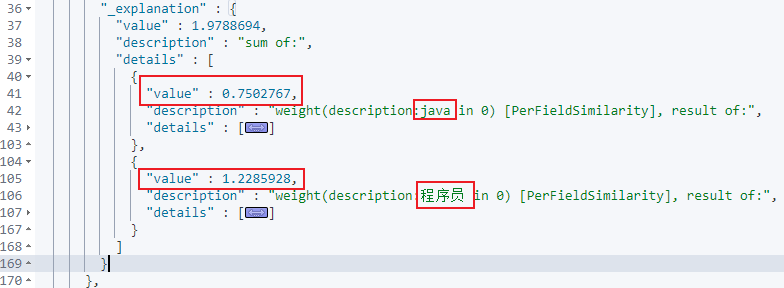
最后将两个关键词合并起来在计算整个doc的总分,即得到最终的_score值,如下所示。
3、document判断是否被匹配
测试判断一个文档能不能被搜索到,适用于生产环境
例如
GET /book/_explain/1
{
"query": {
"match": {
"description": "java程序员"
}
}
}
返回
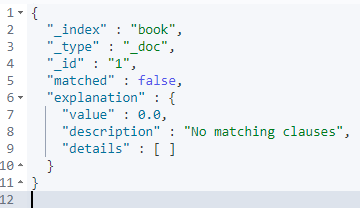
可以看到对于id为1的doc,并不能匹配到该文档,再来试一下id为3的数据
GET /book/_explain/3
{
"query": {
"match": {
"description": "java程序员"
}
}
}
返回
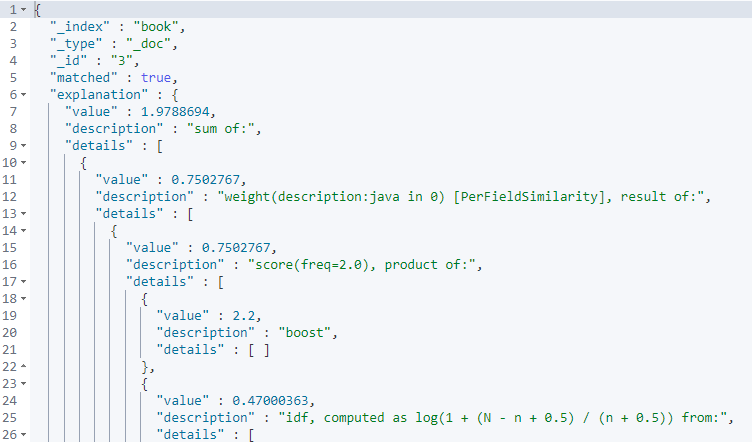
可以看到能够被匹配到,并且能够根据内容来分析为什么该文档能够被匹配到。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: