1 ElasticSearch分布式基础
1.1 ES分布式机制
- 分布式机制:Elasticsearch是一套分布式的系统,分布式是为了应对大数据量。它的特性就是对复杂的分布式机制隐藏掉。
- 分片机制:数据存储到哪个分片,副本数据写入另外分片。
- 集群发现机制:新启动es实例,会自动加入集群。
- shard负载均衡:大量数据写入及查询,es会将数据平均分配。举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求。
- shard副本:新增副本数,分片重分配。
1.2 垂直与水平扩容
垂直扩容:使用更加强大的服务器替代老服务器。但单机存储及运算能力有上线。且成本直线上升。如10台1T的服务器1万,单个10T服务器可能20万。
水平扩容:采购更多服务器,加入集群。对于ES来说,一般采用水平扩容的方式。
1.3 rebalance
当新增或减少es实例时,或者新增加数据或者删除数据时,就会导致某些服务器负载过重或者过轻。es集群就会将数据重新分配,保持一个相对均衡的状态。
1.4 master节点
(1)管理es集群的元数据
- 创建删除节点
- 创建删除索引
(2)默认情况下,es会自动选择一台机器作为master,因为任何一台机器都可能被选择为master节点,所以单点故障的情况可以忽略不计。
1.5 节点对等
- 节点对等,每个节点都能接收所有的请求
- 自动请求路由
- 响应收集
二、分片shard、副本replica机制
2.1 分片shard
在ES中,索引会被切分成n个分片,每个分片是独立的lucene索引,可以完成搜索分析存储等工作。
分片的好处:
- 如果一个索引数据量很大,会造成硬件硬盘和搜索速度的瓶颈。如果分成多个分片,分片可以分摊压力。
- 分片允许用户进行水平的扩展和拆分
- 分片允许分布式的操作,可以提高搜索以及其他操作的效率
副本的好处:
- 当一个分片失败或者下线时,备份的分片可以代替工作,提高了高可用性。
- 备份的分片也可以执行搜索操作,分摊了搜索的压力。
2.2 shard&replica机制
- 每个index包含一个或多个shard
- 每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
- 增减节点时,shard会自动在nodes中负载均衡
- primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
- replica shard是primary shard的副本,负责容错,以及承担读请求负载
- primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
- primary shard的默认数量是1,replica默认是1,默认共有2个shard,1个primary shard,1个replica shard。注意:es7以前primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
- primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
三、创建index
3.1 单node环境下
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index1
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
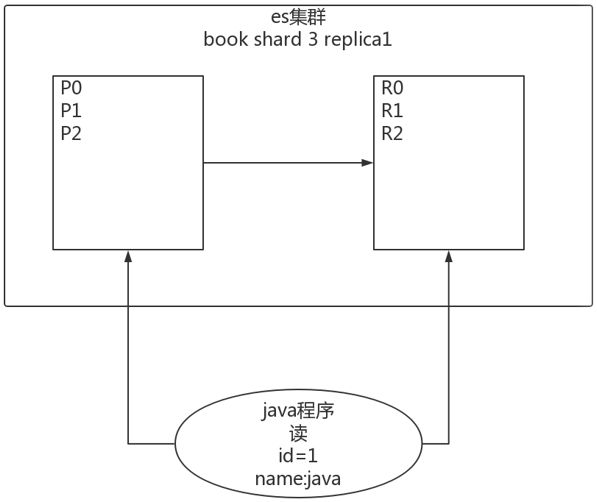
3.2 两个node环境下
(1)replica shard分配:3个primary shard,1node,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica
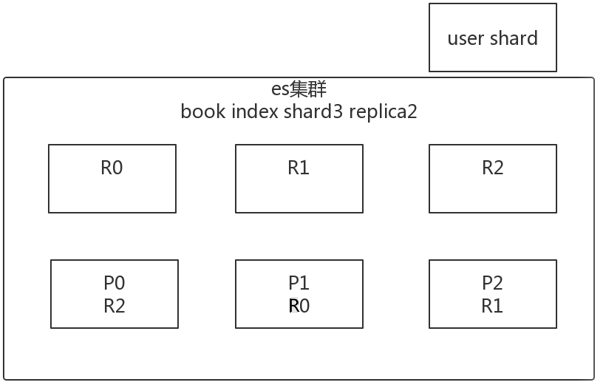
四、横向扩容
假如说存在一个book索引,shard3 replica1
- 分片自动负载均衡,分片向空闲机器转移。
- 每个节点存储更少分片,系统资源给与每个分片的资源更多,整体集群性能提高。
- 扩容极限:节点数大于整体分片数,则必有空闲机器。
- 超出扩容极限时,可以增加副本数,如设置副本数为2,总共3*3=9个分片。9台机器同时运行,存储和搜索性能更强。容错性更好。
- 容错性:只要一个索引的所有主分片在,集群就就可以运行。
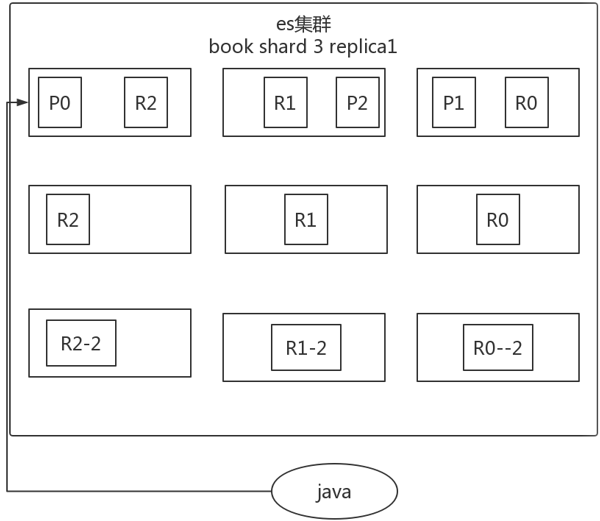
五、es容错机制
以3分片,2副本数,3节点为例介绍。
- master node宕机,自动master选举,集群为red
- replica容错:新master将replica提升为primary shard,yellow
- 重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green
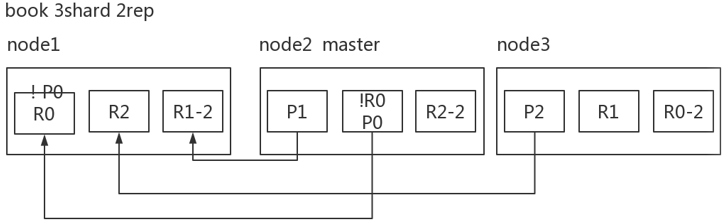
以上图为例:
在node1宕机的情况下,那么P0 shard就会消失,所有的主分片不是全active,那么集群的状态是red。
- 容错第一步,重新选举master节点。承担master相关功能。
- 容错第二步,新master将丢失的P0 shard(主分片)对应的R0 replica(副本分片)提升为主分片,现在的集群状态为yellow并且少一个副本分片,但是现在集群已经可以恢复使用了。
- 容错第三步,重启故障node,新master会感知到新节点加入,将缺失的副本分片copy一份到新的node上面,copy的是被提升为主分片的分片。现在集群已经完全恢复,状态为green。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: