Prometheus
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包 。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。现在,它是一个独立的开源项目,并且独立于任何公司进行维护。为了强调这一点并阐明项目的治理结构,Prometheus在2016年加入了 Cloud Native Computing Foundation,这是继Kubernetes之后的第二个托管项目。
首先,Prometheus是一款时序(time series)数据库,但它的功能却并非止步于TSDB,而是一款设计用于进行目标(Target)监控的关键组件。
结合生态系统内的其它组件,例如Pushgateway、Altermanager和Grafana等,可构成一个完整的IT监控系统。
时序数据库
时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性,往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。
监控分类
我们有很多方法可以进行监视,但主要分为两大类,即黑盒监视和白盒监视。有很多人也叫做是探针(黑盒监控)和内省(白盒监控) 。
黑盒监控
应用程序或主机是从外部观察的,因此,这种方法可能相当有限。
检查是为了评估被观察的系统是否以已知的方式响应探测:
- 主机是否响应PING的请求
- 特定的TCP端口是否打开
- 应用程序在接收到特定的HTTP请求时,是否使用正确的数据和状态代码进行响应?
- 特定应用程序的进程是否在其主机中运行?
白盒监控
系统在被测对象表面显示其内部状态和临界段的性能数据。这种类型的自省可能非常强大,因为它暴露了内部操作,因此不同内部组件的健康状况,否则很难甚至不可能确定。
这种数据处理通常以以下方式处理:
- 通过日志导出:到目前为止,这是也是在广泛引入库之前,应用程序是如何暴露其内部工作的最常见的情况。例如,可以处理HTTP服务器的访问日志来监视请求率、延迟和错误百分比。
- 以结构化的事件输出:这种方法类似于日志记录,但不是将数据写入磁盘,而是直接将数据发送到处理系统进行分析和聚合。
- 以聚合的方式保存在内存中:这种格式的数据可以驻留在端点中,也可以直接从命令行工具中读取。这种方法的例子有/metrics with Prometheus metrics、 HAProxy的stats页面或varnishstats命今行。
特征
普罗米修斯的主要特点是:
- 一个多维数据模型,其中包含通过度量标准名称和键/值对标识的时间序列数据
- PromQL,一种灵活的查询语言 ,可利用此维度
- 不依赖分布式存储;单服务器节点是自治的
- 时间序列收集通过HTTP上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持模式
组件
Promcthcus负责时序型指标数据的采集及存储,但数据的分析、聚合及直观展示以及告警等功能并非由Prometheus Server所负责。
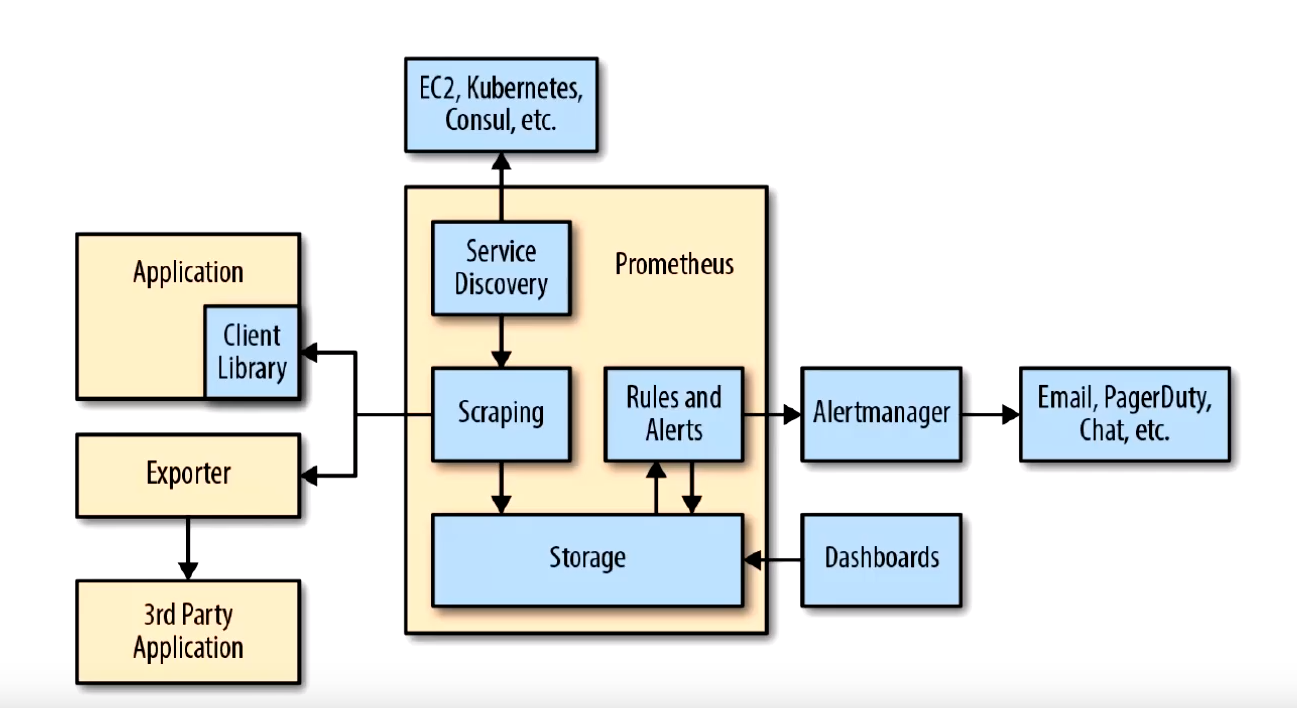
Prometheus生态系统包含多个组件,其中许多是可选的:
- Prometheus server - 收集和存储时间序列数据
- Client Library: 客户端库,为需要监控的服务生成相应的
- metrics 并暴露给 - Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- pushgateway - 对于短暂运行的任务,负责接收和缓存时间序列数据,同时也是一个数据源
- exporter - 各种专用exporter,面向硬件、存储、数据库、HTTP服务等
- alertmanager - 处理报警
- webUI等,其他各种支持的工具,本身的界面值适合用来语句查询,数据可视化,需要第三方组件,比如Grafana。
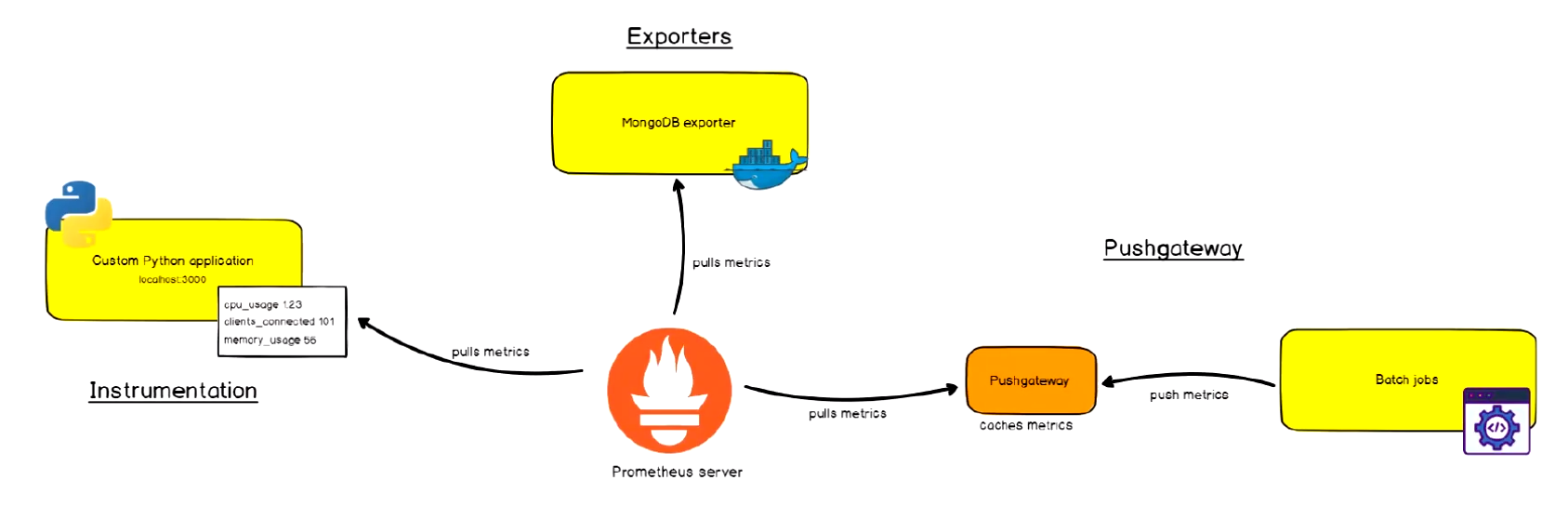
架构
下图说明了Prometheus的体系结构及其某些生态系统组件:
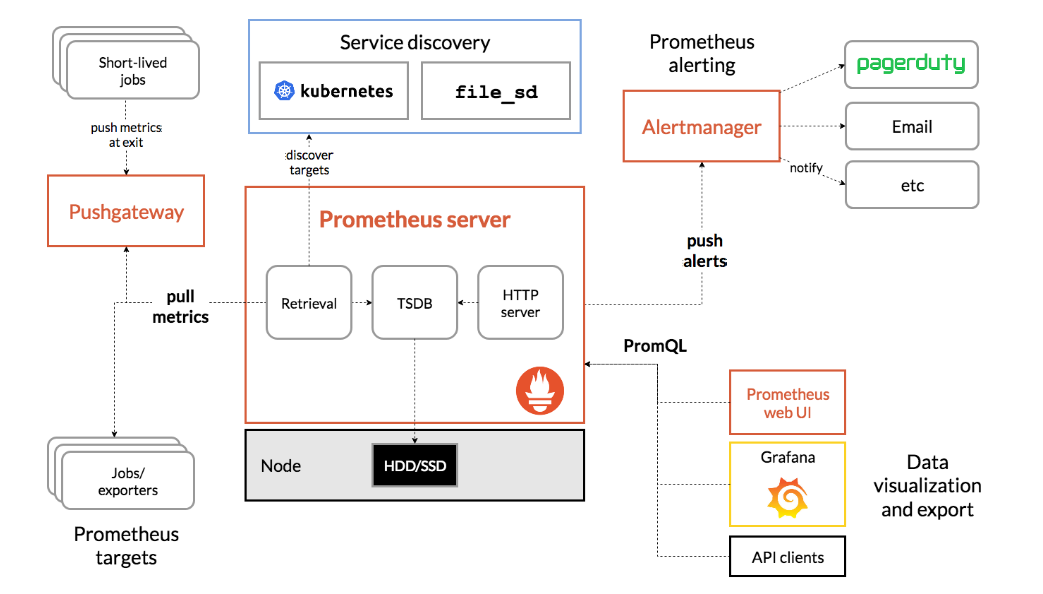
Prometheus直接或通过中间推送网关从已检测的作业中删除指标,以处理短暂的作业。它在本地存储所有报废的样本,并对这些数据运行规则,以汇总和记录现有数据中的新时间序列,或生成警报。Grafana或其他API使用者可以用来可视化收集的数据。
如何收集度量值
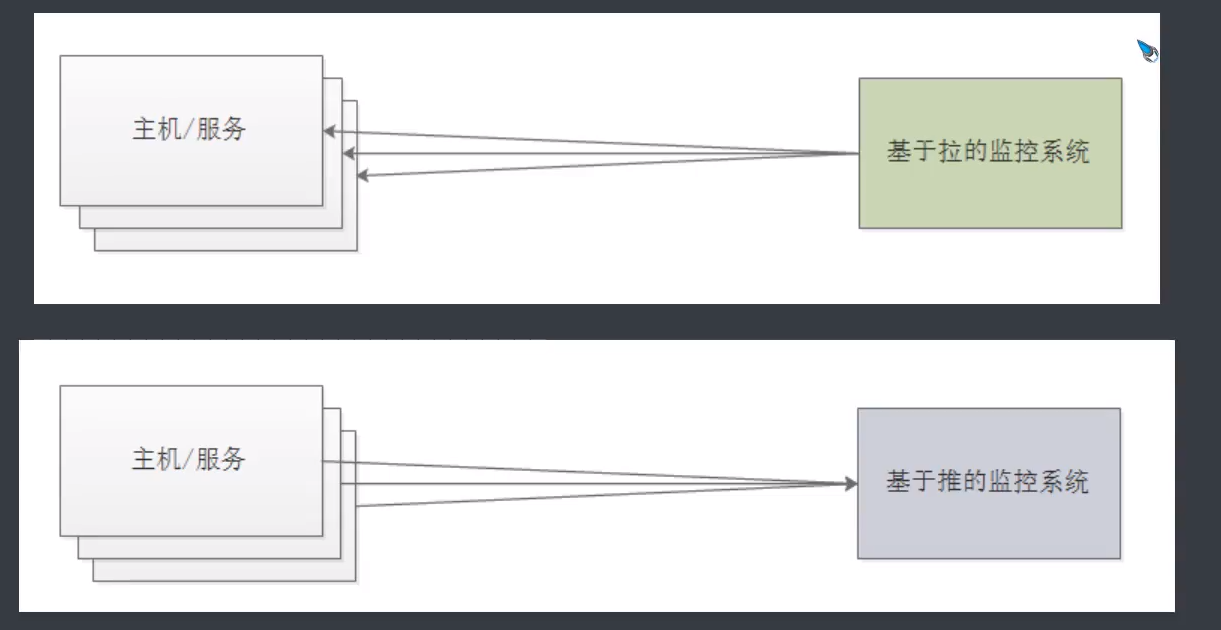
度量指标由监控系统执行的过程通常可以分为两种方法:推和拉。
Prometheus基于HTTP call,从配置文件中指定的网络端点(endpoint)上周期性获取指标数据。
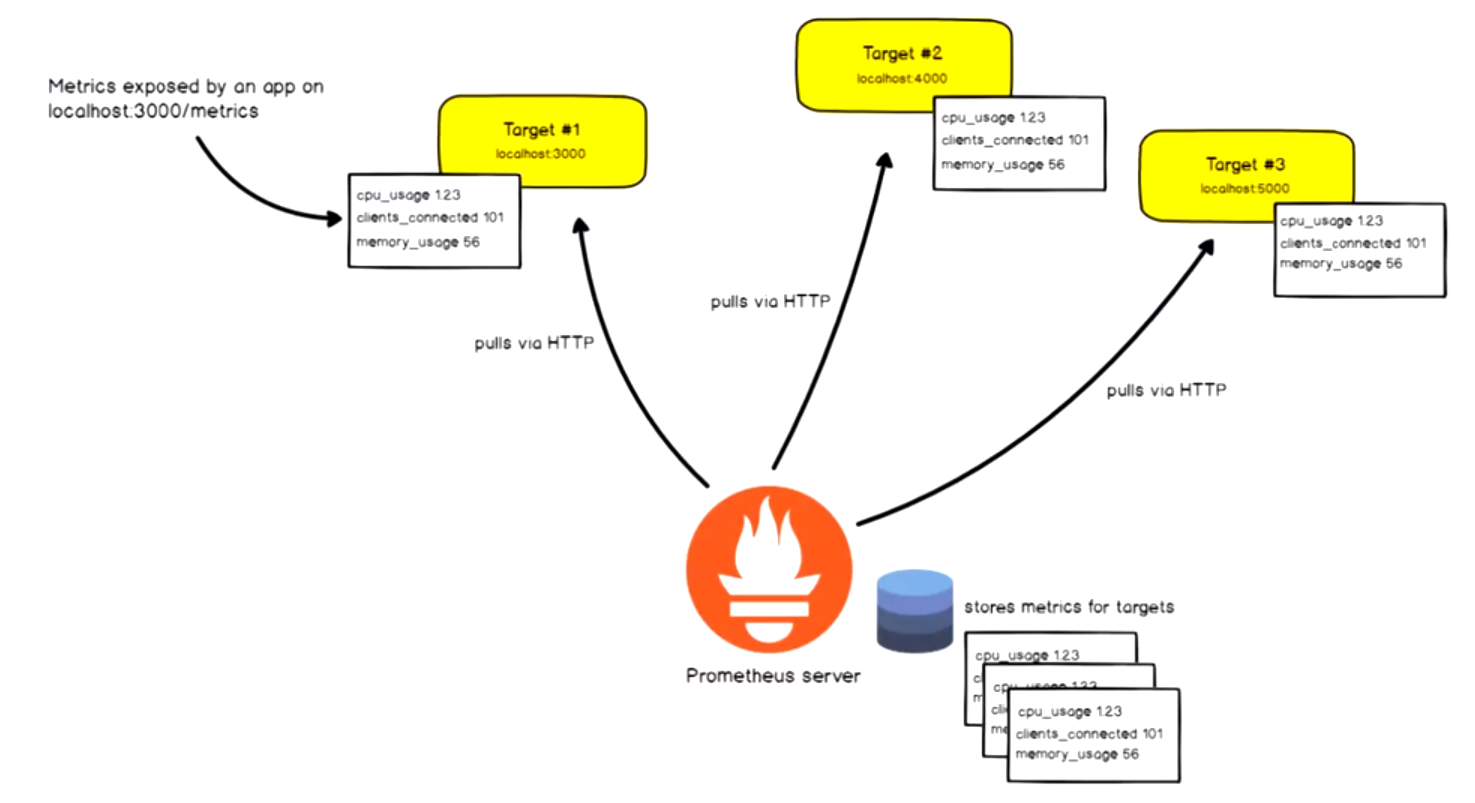
Prometheus支持通过三种类型的途径从目标上“抓取(Serape)”指标数据:
- Exporters:被监控的目标不支持pro的数据格式,通过exporters抽取指标数据,进行格式化处理成pro兼容的数据格式,再响应给pro server。
- Instrumentation:应用系统内建了pro兼容的指标数据格式,pro server可以直接采集。
- Push gateway:pro采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。暂存在pushgateway,等待Prometheus server拉取。
指标类型
Promcthcus使用4种方法来描述监视的指标。
计数器
Counter:计数器,用于保存单调递增型的数据,例如站点访问次数等;不能为负值,也不支持减少,但可以重置回0;
比如网络总访问数。
仪表盘
Gauge:仪表盘,用于存储有着起伏特征的指标数据,例如内存空闲大小等。
Gauge是Counter的超集;但存在指标数据丢失的叮能性时,Counter能让用户确切了解指标随时间的变化状态,而Gauge则可能随时问流逝而精准度越来越低。
比如CPU的使用率:
直方图
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
Histogram常常用于观察,一个Histrogram包含下列值的合并:
- Buckets:桶是观察的计数器。它应该有个最大值的边界和最小值的边界。它的格式为basename> _bucket
- 观察结果的和,这是所有观案的和。针对它的格式是《basename>_sum
- 观察结果统计,这是在本次观察的和。它的格式为《basename>_count
Summary
Summary与Histogram类型类似,用于表示段时间内的数据采集结果(通常是请求持或时间或响应大小),但它直接存储了分位数通过客户端计算,然后展示出来,而不是通过区间来计算。
指标摘要及聚合
指标摘要
通常米说,单个指标对我们价值很小,往往需要联合并可视化多个指标,这其中需要一些数学变换,例如,我们可能会统计函数应用于指标或指标组,一些可能应用常见函数包括:
- 计数:计算特定时间间降内的观索点数,
- 求和:将特定时间间隔内所有观察点的值累计相加。
- 平均值,提供特定时间间隔内所有伯的平均值,
- 中间数:数值的几何中点,正好50%的数值位于它前面,而另外50%则位于它后面,
- 百分位数:度量占总数特定百分比的观察点的值。
- 标准差:显示指标分布中与平均值的标准差,这可以测量出数据集的差异程度。标准差为0表示数据都等于平均值较高的标准兰意味着数据分布的范围很广
- 变化率:显示时间序列中数据之间的变化程度。
指标聚合
除了上述的指标描要外,你可能经常希望能看到来自当个源的指标的聚合图,例如所有应用程序服务器的磁盘空间使用情况。指标聚合最典型的样式就是在一张图上显示多个指标,这有助于你识别环境的发展趋势。
例如,负载均衡器中的问歇性故障可能导致多个服务器的Web流量下降,这通常比通过查看每个单独的指标更容易发现。

Docker 安装Prometheus
docker run --name prometheus -d -p 9500:9090 prom/prometheus
Docker Compose安装Prometheus
在docker-compose.yml文件目录下,创建prometheus/conf/prometheus.yml文件,添加配置,将配置文件映射到主机。
prometheus.yml:
# 全局配置
global:
# 抓取数据的时间间隔
scrape_interval: 60s
# 监控规则的时间间隔
evaluation_interval: 15s
# 数据抓取的超时时间
# scrape_timeout 10s
# Alertmanager配置 无需配置 使用Granfana
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 服务器加载规则的位置
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 监控资源配置
scrape_configs:
# prometheus监控
- job_name: 'prometheus' # 定义采集任务名称
static_configs:
- targets: ['localhost:9090'] # 采集节点地址 多个采用数组
version: '3'
services:
# prometheus
prometheus:
image: /prom/prometheus:v2.30.0
container_name: prometheus
hostname: prometheus
restart: always
user: root
ports:
- "9090:9090"
volumes:
- ./prometheus/conf/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
networks:
- ops
networks:
ops:
driver: bridge
压缩包安装Prometheus
1、 下载地址(根据操作系统选择):https://prometheus.io/download/;
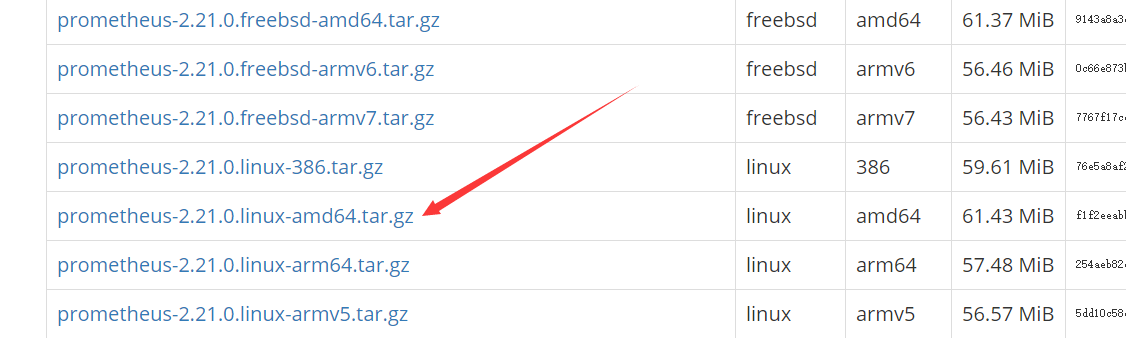
2、 安装;
# 上传压缩包
# 解压
tar -zxvf prometheus-2.21.0.linux-amd64.tar.gz
mv prometheus-2.21.0.linux-amd64/ prometheus-2.21.0
cd prometheus-2.21.0
# 查看帮助
./prometheus -h
1、 启动;
./prometheus --web.listen-address=:9500 &
1、 访问首页;
Prometheus 文件
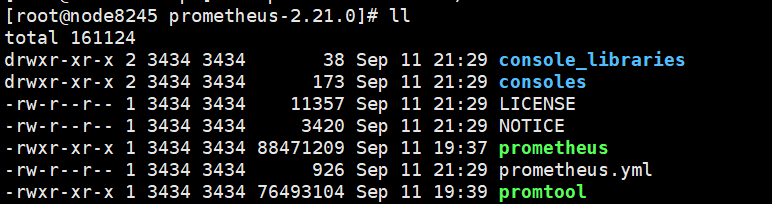
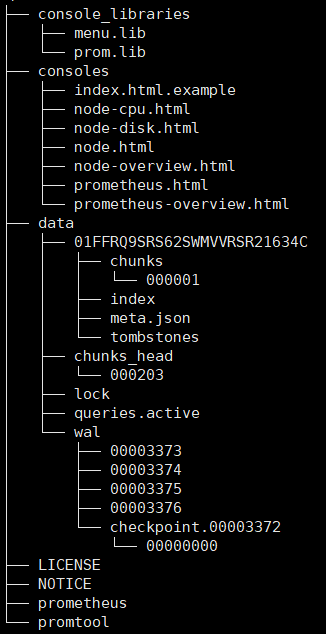
Prometheus安装包包含了以下图中文件。
主要有:
- console_libraries:控制台依赖库
- consoles:控制台前端页面
- data:数据数据库文件
- prometheus:prometheus本身启动文件
- promtool:prometheus工具启动文件
资料地址
官网:https://prometheus.io/
Github: https://github.com/prometheus/prometheus
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: