数据模型(DATA MODEL)
之前我们了解到Prometheus采用时间序列数据库TSDB存储数据,所有数据存储为时序数据,即按照相同时序(time series)以时间维度存储的连续数据的集合。除了存储的时间序列,Prometheus 可能会生成临时派生的时间序列作为查询的结果。
Prometheus时间序列
时间序列数据:按照时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本。
数据采集以特定的时间周期进行,因而,随着时间流逝,将这些样本数据记录下来,将生成一个离散的样本数据序列。
该序列也称为向量(Vector),而将多个序列放在同一个坐标系内(以时间为横轴,以序列为纵轴),将形成一个由数据点组成的矩阵。
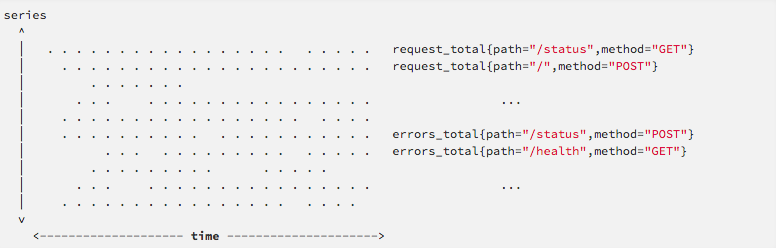
指标名称及标签(Metric names and labels)
每个时间序列都由metric名称和键值对labels(标签)作为唯一标识。
比如对于某个服务器内存空闲指标node_memory_MemFree_bytes,在采集前是这个样子

我们在控制台查询可以看到,在Prometheus存储时,将指标名称和标签组成了一个时间序列名,其对应的值为抓取到的数据。
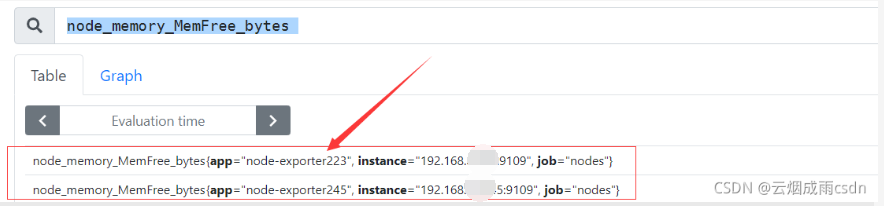
每个时间序列都由指标名称(Metric Name)和标签(Labe)来唯一标识,格式为:
“< metric name>{
< label name>=< label value>}”
指标名称:通常用于描述系统上要测定的某个特征,例如,htp_requcsts_total表示接收到的HTTP请求总数,支持使用字母、数字、下划线和冒号,且必须能匹配RE2规范的正则表达式。
Metric Name的表示方式有两种,后一种通常用于Prometheus内部:

标签:键值型数据,附加在指标名称之上,从而让指标能够支持多纬度特征,例如http_requests_total {method=GET}和ttp_requests_total{method=POST}代表着两个不同的时间序列,标签名称可使用字母、数字和下划线,且必须能匹配RE2规范的正则表达式。
Prometheus就会按照时间顺序,以时序名称(指标名称+标签)记录其变化信息,每个数据称为一个样本(Samples)。
Prometheus的每个数据样本由两部分组成:
- float64格式的数据
- 毫秒精度的时间戳

从下图中,可以很清楚的看到当前时序数据,包含了时序名称、时间戳及当前时间对应的值。
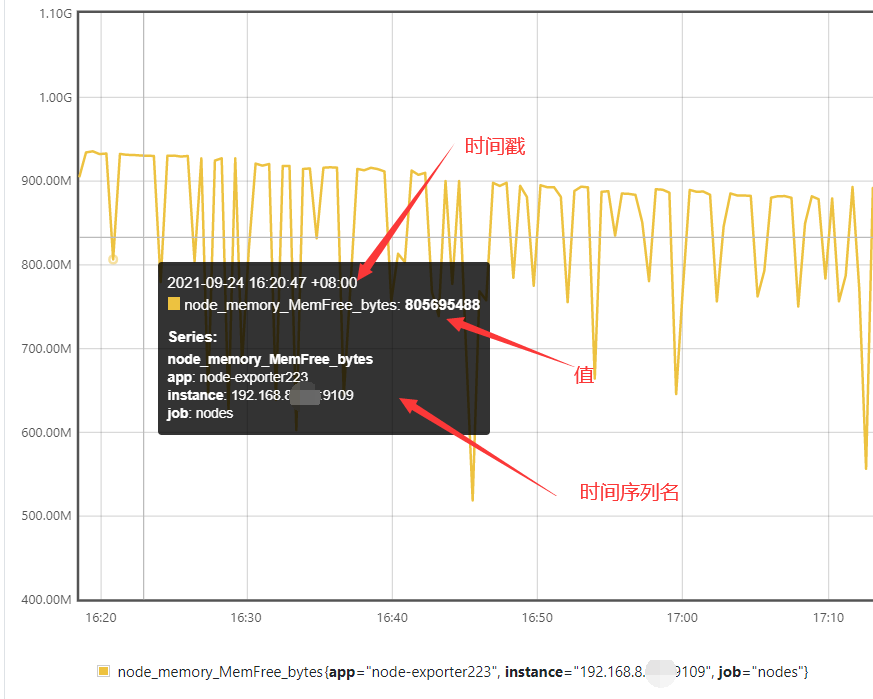
指标名称及标签使用注意事项
指标名称和标签的特定组合代表着一个时间序列:
- 指标名称相同,但标签不同的组合分别代表着不同的时间序列;
- 不同的指标名称自然更是代表着不同的时间序列;
PromQL支持基于定义的指标维度进行过滤和聚合:
- 更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列;
- 应该尽可能地保持标签的稳定性,否则,则很可能创建新的时间序列,更甚者会生成一个动态的数据环境,并使得监控的数据源难以跟踪,从而导致建立在该指标之上的图形、告警及记录规则变得无效;
指标类型(METRIC TYPES)
Prometheus 客户端库提供四种核心指标类型。
Counter(计数器)
计数器,单调递增,除非重置(例如服务器或进程重启)。可以使用计数器来表示服务的请求数、完成的任务数或错误数。不要使用计数器来公开可以减少的值,例如,不要对当前运行的进程数使用计数器,而是使用仪表。
通常,Counter的总数并没有直接作用,而是需要借助于rate、topk、increase和irate等函数来生成样本数据的变化状况(增长率)。
获取2小时内,该指标下各时间序列上的http总请求数的增长速率:
rate(http_requests_total[2h])
获取该指标下http请求总数排名前3的时间序列:
topk(3,http_requests_total)
高灵敏度函数,用于计算指标的瞬时速率:
irate(http_requests_total[2h])
基于样本范围内的最后两个样本进行计算,相较于rate函数来说,irate更适用于短期时间范围内的变化速率分析。
Gauge(仪表盘)
Gauge 类型代表一个可以任意变化的指标数据,其可增可减。在应用场景中,像是 Go 应用程序运行时的 Goroutine 的数量就可以用该类型来表示,在系统中统计 CPU、Memory 等等时很常见,而在业务场景中,业务队列的数量也可以用 Gauge 来统计,实时观察队列数量,及时发现堆积情况,因为其是浮动的数值,并非固定的,侧重于反馈当前的情况。
Gauge用于存储其值可增可减的指标的样本数据,常用于进行求和、取平均值、最小值、最大值等聚合计算,也会经常结合PromQL的predic_linear和deta函数使用。
predict_lincar(v range-vector, t,scalaR)函数可以预测时间序列v在t秒后的值,它通过线性回归的方式来预测样本数据的Gauge变化趋势。
delta(v range-vector)函数计算范围向量中每个时间序列元素的第一个值与最后一个值之差,从而展示不同时间点上的样本值的差值。
deta(cpu_tempcelsius{host=“web01.magedu.com”}[2h]),返回该服务器上的CPU温度与2小时之前的差异。
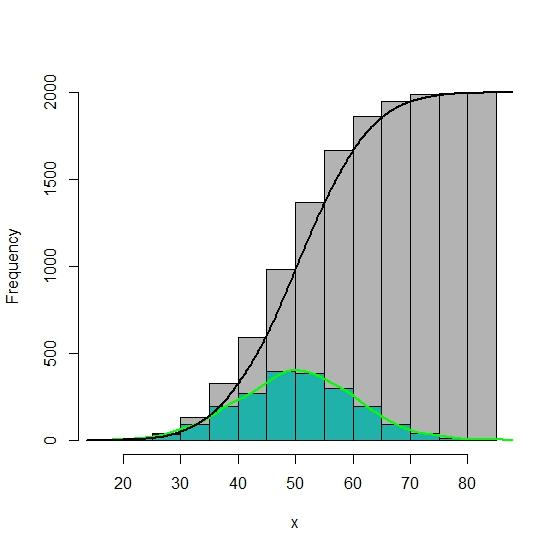
Histogram(直方图)
Histogram 类型将会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数。
Histogram 类型在应用场景中非常的常用,因为其代表的就是分组区间的统计,而在分布式场景盛行的现在,链路追踪系统是必不可少的,那么针对不同的链路的分析统计就非常的有必要,例如像是对 RPC、SQL、HTTP、Redis 的 P90、P95、P99 进行计算统计,并且更进一步的做告警,就能够及时的发现应用链路缓慢,进而发现和减少第三方系统的影响。
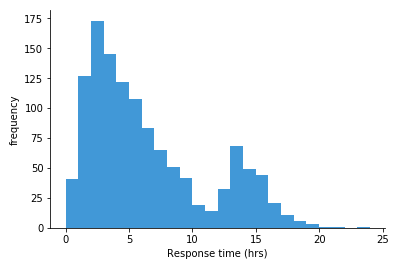
Histogram是一种对数据分布情况的图形表示,由一系列高度不等的长条图(bar)或线段表示,用于展示单个测度的值的分布。
它一般用横轴表示某个指标维度的数据取值区间,用纵轴表示样本统计的频率或频数,从而能够以二维图的形式展现数值的分布状况。
为了构建Histogram,首先需要将值的范围进行分段,即将所有值的整个可用范围分成一系列连续、相邻(相邻处可以是等同值)但不重叠的间隔,而后统计每个间隔中有多少值。
从统计学的角度看,分位数不能被聚合,也不能进行算术运算。
对于Prometheus来说,Histogram会在一段时间范围内对数据进行采样(通常是请求持续时长或响应大小等),并将其计入可配置的bucket(存储桶)中。
Histogram事先将特定测度可能的取值范围分隔为多个样本空间,并通过对落入bucket内的观测值进行计数以及求和操作。
与常规方式略有不同的是,Prometheus取值间隔的划分采用的是累积(Cumulative)区间间隔机制,即每个bucket中的样本均包含了其前面所有bucket中的样本,因而也称为累积直方图。可降低Histogram的维护成本,支持粗略计算样本值的分位数,单独提供了_sum和_count指标,从而支持计算平均值。
Histogram类型的每个指标有一个基础指标名称< basename>,它会提供多个时间序列:
< basename>_bucket{le="< upper incusive bound>"}:观测桶的上边界(upper inclusive bound),即样本统计区间,最大区间(包含所有样本)的名称为< basename>_bucket{le="+Inf"};< basename>_sum:所有样本观测值的总和;< basename>_count:总的观测次数,它自身本质上是一个Counter类型的指标;
累积间隔机制生成的样本数据需要额外使用内置的histogram_quantile()函数即可根据Histogram指标来计算相应的分位数(quantile),即某个bucket的样本数在所有样本数中占据的比例。
histogram_quantile()函数在计算分位数时会假定每个区间内的样本满足线性分布状态,因而它的结果仅是一个预估值,并不完全准确。
预估的准确度取决于bucket区间划分的粒度,粒度越大,准确度越低。
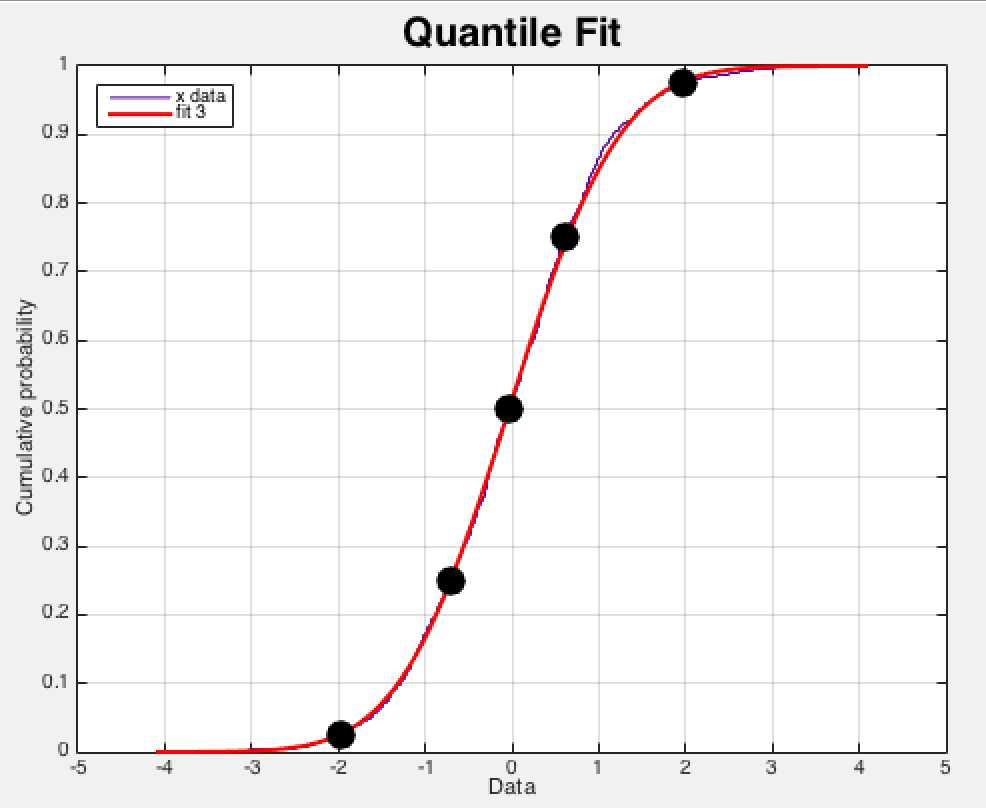
Summary(概要)
Summary 类型将会在一段时间范围内对数据进行采样,但是与 Histogram 类型不同的是 Summary 类型将会存储分位数(在客户端进行计算),而不像 Histogram 类型,根据所设置的区间情况统计存储。提供三种摘要指标: 样本值的分位数分布情况,所有样本值的大小总和,样本总数。
指标类型是客户端库的特性,而Histogram在客户端仅是简单的桶划分和分桶计数,分位数计算由Prometheus Server基于样本数据进行估算,因而其结果未必准确,甚至不合理的bucket划分会导致较大的误差。
Summary是一种类似于Histogram的指标类型,但它在客户端于一段时间内(默认为10分钟)的每个采样点进行统计,计算并存储了分位数数值,Server端直接抓取相应值即可。
但Summary不支持sum或avg一类的聚合运算,而且其分位数由客户端计算并生成Server端无法获取客户端未定义的分位数,而Histogram可通过PromQL任意定义,有着较好的灵活性。
对于每个指标,Summary以指标名称< basename>为前缀,生成如下几个指标序列
-
< basename>{quantile=-"< p>",其中p是分位点,其取值范围是(0≤p≤1);计数器类型指标;如下是几种典型的常用分位点: -
0、0.25、0.5、0.75和1几个分位点;
-
0、0.90、0.99几个分位点;
-
0.01、0.05、0.5、0.9和0.99几个分位点;
-
< basename>_sum,抓取到的所有样本值之和; -
< basename>_count,抓取到的所有样本总数;
PromQL
简介
PromQL (Prometheus Query Language)是Prometheus Server内置数据查询语言PromQL,使用表达式( expression)来表述查询需求。
根据其使用的指标和标签,以及时间范围,表达式的查询请求可灵活地覆盖在一个或多个时间序列的一定范围内的样本之上,甚至是只包含单个时间序列的单个样本。
在Prometheus 的表达式语言中,支持一下四种基本数据类型:
- 即时向量(Instant Vector):特定或全部的时间序列集合上,具有相同时间戳的一组样本值称为即时向量;
- 范围向量(Range Vector):特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值;
- 标量(Scalar) :一个浮点型的数据值。
- 字符串(String) : 一个简单的字符串值,支持使用单引号、双引号或反引号进行引用,但反引号中不会对转义字符进行转义;
根据用例(例如,当绘制与显示表达式的输出时),作为用户指定表达式的结果,这些类型中只有一些是合法的。例如,返回即时向量的表达式是唯一可以直接绘制的类型。
字面量
1. 字符串
字符串可以在单引号、双引号或反引号中指定为文字。
PromQL 遵循与Go相同的转义规则。在单引号或双引号中,反斜杠开始一个转义序列,后面可以跟a, b, f, n, r, t,v或\。可以使用八进制 ( \nnn) 或十六进制 ( \xnn,\unnnn和\Unnnnnnnn)提供特定字符。
反引号内不处理转义。与 Go 不同,Prometheus 不会丢弃反引号内的换行符。
例子:
"this is a string"
'these are unescaped: \n \\ \t'
these are not unescaped: \n ' " \t
2. 浮点类型
指标浮点值可以写成文字整数或浮点数。
例子:
23
-2.43
3.4e-9
0x8f
-Inf
NaN
向量选择器
PromOL的查询操需要针对有限个时间序列上的样本数据进行,挑选出目标时间序列是构建表达式时最为关键的一步。
用户使用向量选择器表达式来挑选出给定指标名称下的所有时间序列或部分时间序列的即时(当前)样本值或至过去某个时间范围内的样本值,前者称为即时向量选择器,后者称为范围向量选择器。
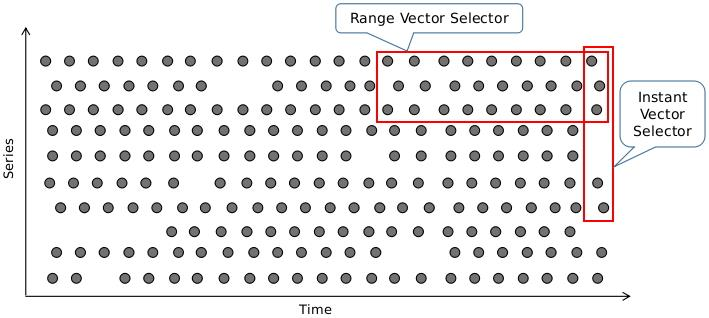
1. 即时(当前)向量选择器
即时向量选择器(Instant Vector Sclectors)返回0个、1个或多个时间序列上在给定时间戳(instant)上的各自的一个样本,该样本也可称为即时样本。
即时向量选择器由两部分组成;
- 指标名称:用于限定特定指标下的时间序列,即负责过滤指标(可选)。
- 匹配器 (Matcher):或称为标签选择器,用于过滤时间序列上的标签;定义在l之中(可选)。
在最简单的形式中,只指定一个指标名称,这会产生一个包含所有具有此指标名称的时间序列元素的即时向量。
此示例选择具有http_requests_total指标名称的所有时间序列:
http_requests_total
可以通过在花括号 ( {}) 中附加逗号分隔的标签匹配器列表来进一步过滤这些时间序列。
此示例仅选择具有http_requests_total 度量名称且job标签设置为prometheus且 group标签设置为canary的时间序列:
http_requests_total{
job="prometheus",group="canary"}
也可以否定匹配标签值,或将标签值与正则表达式匹配。存在以下标签匹配运算符:
- =:选择与提供的字符串完全相同的标签。
- !=:选择不等于提供的字符串的标签。
- =~:选择与提供的字符串正则表达式匹配的标签。
- !~:选择与提供的字符串不匹配的标签。
例如,选择所有HTTP方法不等于GET,以及environment为staging、testing、development中的向量。
http_requests_total{
environment=~"staging|testing|development",method!="GET"}
匹配空标签值的标签匹配器会选择没有设置特定标签的所有时间序列。而正则表达式匹配是完全支持的。同一个标签名称可以有多个匹配器。
向量选择器必须指定一个名称或至少一个与空字符串不匹配的标签匹配器。以下表达式是非法的:
{
job=~".*"} # Bad!
相反,这些表达式是有效的,因为它们都有一个不匹配空标签值的选择器。
{
job=~".+"} # Good!
{
job=~".*",method="get"} # Good!
标签匹配器也可以通过与内部__name__标签匹配来应用于指标名称 。例如,表达式http_requests_total等效于 { name=“http_requests_total”}。也可以使用=( !=, =~, !~)以外的匹配器。
以下表达式选择名称以job开头的所有指标:
{
__name__=~"job:.*"}
指标名称不能是关键词之一bool,on,ignoring,group_left和group_right。以下表达式是非法的:
on{
} # Bad!
此限制的解决方法是使用__name__标签:
{
__name__="on"} # Good!
Prometheus 中的所有正则表达式都使用RE2 语法。
2. 范围向量选择器
范围向量选择器(Range Vector Selectors)返回0个、1个或多个时间序列上在给定时间范围内的各自的一组样本。
范围向量字面量的工作方式与即时向量字面量类似,不同之处在于它们从当前时刻选择了一系列样本。从语法上讲,持续时间在向量选择器的末尾附加在方括号 []中,以指定应该为每个结果范围向量元素提取多远的时间值。
在此示例中,我们选择了我们在过去 5 分钟内为指标名称http_requests_total和job标签设置为 prometheus的所有时间序列记录的所有值:
http_requests_total{
job="prometheus"}[5m]
持续时间指定为一个数字,后跟以下单位之一:
- ms - 毫秒
- s - 秒
- m - 分钟
- h - 小时
- d - days - 假设一天总是 24 小时
- w - 周 - 假设一周总是 7d
- y - 年 - 假设一年总是 365d
持续时间可以通过串联来组合。单位必须按从最长到最短的顺序排列。给定的单位在一段时间内只能出现一次。
以下是一些有效持续时间的示例:
5h
1h30m
5m
10s
偏移量修改器
默认情况下,即时向量选择器和范围向量选择器都以当前时间为基准时间点,而偏移量修改器能够修改该基准。偏移量修改器的使用方法是紧跟在选择器表达式之后使用“offset”关键字。

例如,以下表达式返回 http_requests_total过去 5 分钟相对于当前查询评估时间的值:
http_requests_total offset 5m
请注意,offset修饰符总是需要跟随选择器,即以下是正确的:
sum(http_requests_total{
method="GET"} offset 5m) // GOOD.
虽然以下内容是不正确的:
sum(http_requests_total{
method="GET"}) offset 5m // INVALID.
这同样适用于范围向量。这将返回http_requests_total一周前的 5 分钟费率 :
rate(http_requests_total[5m] offset 1w)
为了与时间上的时间前移进行比较,可以指定负偏移量:
rate(http_requests_total[5m] offset -1w)
此功能通过设置–enable-feature=promql-negative-offset 标志启用。
@修饰符
在Prometheus v2.25.0中,我们引入了一个新的PromQL修饰符@。与offset修饰符让你对向量选择器、范围向量选择器和子查询的求值进行相对于求值时间的固定时间偏移类似,@修饰符让你对这些选择器的求值进行固定,而不考虑查询求值时间。
例如,以下表达式返回http_requests_totalat的值 2021-01-04T07:40:00+00:00:
http_requests_total @ 1609746000
请注意,@修饰符总是需要跟随选择器,即以下是正确的:
sum(http_requests_total{
method="GET"} @ 1609746000) // GOOD.
虽然以下内容是不正确的:
sum(http_requests_total{
method="GET"}) @ 1609746000 // INVALID.
这同样适用于范围向量。例如返回5分钟的 http_requests_total在2021-01-04T07:40:00+00:00时间内的比率:
rate(http_requests_total[5m] @ 1609746000)
它也可以与offset修改器一起使用,其中偏移是相对于@ 修改器时间应用的,而不管哪个修改器首先被写入。这两个查询将产生相同的结果。
### offset after @
http_requests_total @ 1609746000 offset 5m
# offset before @
http_requests_total offset 5m @ 1609746000
@修饰符默认是禁用的,可以使用标志–enable-feature=promql-at-modifier来启用。
此外,start()和end()还可以用作@修改的值作为特殊值。
对于范围查询,它们分别解析为范围查询的开始和结束,并在所有步骤中保持不变。
对于即时查询,start()和end()都解析为计算时间。
http_requests_total @ start()
rate(http_requests_total[5m] @ end())
子查询
子查询允许您对给定的范围和分辨率运行即时查询。子查询的结果是一个范围向量。
语法: <instant_query> '[' <range> ':' [<resolution>] ']' [ @ <float_literal> ] [ offset <duration> ]
操作符
Prometheus支持二元和聚合操作符。
函数
Prometheus提供了一些函数列表操作时间序列数据。
注释
PromQL 支持以#为注释,例子:
# This is a comment
陷阱
运行查询时,独立于实际当前时间序列数据选择采样数据的时间戳。这主要是为了支持聚合(总和,平均等)这样的情况,其中多个聚合时间序列在时间上不完全对齐。由于它们的独立性,Prometheus需要在每个相关时间序列的时间戳上分配值。它只需在此时间戳之前采用最新的样本即可。
如果目标抓取或规则评估不再返回先前存在的时间序列的样本,则该时间序列将被标记为陈旧。如果目标被移除,之前很快就会将其先前返回的时间序列标记为陈旧。
如果在时间序列标记为过时后在采样时间戳处评估查询,则不会为该时间系列返回任何值。如果随后在该时间序列中摄取新样本,它们将照常返回。
如果在采样时间戳前5分钟未找到任何样本(默认情况下),则此时间点不返回该时间序列的值。这实际上意味着时间序列在其最新收集的样本超过5分钟或标记为陈旧之后从图表“消失”。
对于在其抓取中包含时间戳的时间序列,不会标记陈旧性。在这种情况下,仅应用5分钟的阈值。
避免慢查询和重载
如果查询需要对大量数据进行操作,则绘制图表可能会超时或使服务器或浏览器过载。因此,在构建对未知数据的查询时,始终在Prometheus表达式浏览器的表格视图中开始构建查询,直到结果集看起来合理(最多数百个,而不是数千个时间序列)。只有在您充分过滤或汇总数据后,才能切换到图表模式。如果表达式仍然需要很长时间来绘制ad-hoc图形,请通过录制规则预先录制它。
这与Prometheus的查询语言尤其相关,其中像api_http_requests_total这样的简单度量标准名称选择器可以扩展到具有不同标签的数千个时间序列。还要记住,即使输出只是少量的时间序列,聚合在许多时间序列上的表达式也会在服务器上产生负载。这类似于在关系数据库中对列的所有值求和的速度很慢,即使输出值只是一个数字。
参考文档
https://fuckcloudnative.io/prometheus/3-prometheus/basics.html
https://prometheus.io/docs/prometheus/latest/querying/basics/
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: