分组(Grouping)及路由(route)
简介
分组将类似性质的警报分类为单个通知。当许多系统同时发生故障并且可能同时触发数百到数千个警报时,这在较大的中断期间尤其有用。
示例:当发生网络分区时,集群中正在运行数十个或数百个服务实例。您的一半服务实例无法再访问数据库。Prometheus 中的警报规则被配置为在每个服务实例无法与数据库通信时发送警报。因此,数百个警报被发送到 Alertmanager。
作为用户,您只想获得一个页面,同时仍然能够准确查看哪些服务实例受到影响。因此,可以将 Alertmanager 配置为按集群和警报名称对警报进行分组,以便它发送单个紧凑通知。
警报分组、分组通知的时间以及这些通知的接收者由配置文件中的路由树进行配置。
配置项
配置项如下:
# 设置默认接收人
[ receiver: <string> ]
# 用于将传入警报分组在一起的标签。
[ group_by: '[' <labelname>, ... ']' ]
# 警报是否应继续匹配后续同级节点。
[ continue: <boolean> | default = false ]
# 不推荐使用下面的匹配器。
# 警报必须满足的一组相等匹配器来匹配节点。
match:
[ <labelname>: <labelvalue>, ... ]
# 不推荐,警报必须满足的一组正则表达式匹配器来匹配节点。
match_re:
[ <labelname>: <regex>, ... ]
# 警报必须完成以匹配节点的匹配器列表。
matchers:
[ - <matcher> ... ]
# 为组发送通知的初始等待时间
# 警报数量。允许等待禁止警报到达或收集,同一组的更多初始警报。(通常为~0到几分钟。)
[ group_wait: <duration> | default = 30s ]
# 在发送有关新警报的通知之前需要等待多长时间
[ group_interval: <duration> | default = 5m ]
# 如果已发送通知,则在再次发送通知之前要等待多长时间,通常约3小时或更长时间
[ repeat_interval: <duration> | default = 4h ]
# 应禁用路由的时间。这些文件必须与文件名匹配
mute_time_intervals:
[ - <string> ...]
# 零个或多个子路由。
routes:
[ - <route> ... ]
流程分析
路由块定义路由树中的一个节点及其子节点。如果未设置,其可选配置参数将从其父节点继承。
每个警报在配置的顶级路由处进入路由树,该路由树必须匹配所有警报(即没有任何配置的匹配器)。然后遍历子节点。如果continue设置为 false,它会在第一个匹配的孩子之后停止。如果continue在匹配节点上为 true,则警报将继续与后续兄弟节点匹配。如果警报与节点的任何子节点都不匹配(没有匹配的子节点或不存在),则根据当前节点的配置参数处理警报。
抑制( Inhibition)
概念
抑制是一个概念,如果某些其他警报已经触发,则抑制某些警报的通知,可以有效的防止告警风暴。
配置项
通过Alertmanager 的配置文件进行配置,配置项为inhibit_rules,很多配置项已经过时,所以这里只有三个配置项,可以配置的内容如下:
# 要禁用的目标警报必须满足的匹配器列表。
target_matchers:
[ - <matcher> ... ]
# 必须存在一个或多个警报才能使抑制生效的匹配器列表。
source_matchers:
[ - <matcher> ... ]
# 要使抑制生效,源警报和目标警报中必须具有相等值的标签。
[ equal: '[' <labelname>, ... ']' ]
案例演示
1. 模拟环境
首先我们部署了服务器和Nacos的监控,如果服务器宕机,此时Nacos肯定也挂掉了,这个时候就应该抑制Nacos告警。之前案例中,我们已经接入了Naocs和Windows服务器。

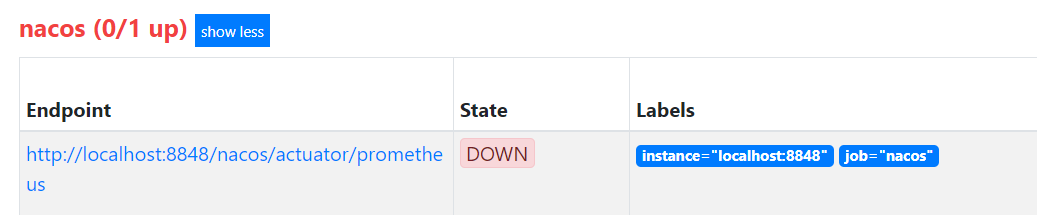
在Promethues的规则文件中,添加告警规则
groups:
- name: alters
rules:
- alert: Nacos Down
# expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
expr: up{
job="nacos"} == 0
for: 1m
labels:
severity: emergency
target: nacos
host: localhost
annotations:
description: "description"
summary: "{
{ $labels.instance }} 已停止运行超过 1 分钟!"
- alert: System Down
expr: up{
job="wins"} == 0
for: 1m
labels:
severity: emergency
target: wins
host: localhost
annotations:
description: "description"
summary: "{
{ $labels.instance }} 已停止运行超过 1 分钟!"
重新启动Promethues,然后再任务管理器中,停掉我们windows_exporter(因为部署在自己电脑上,所以关闭这个,模拟服务器宕机),再关闭Nacos。
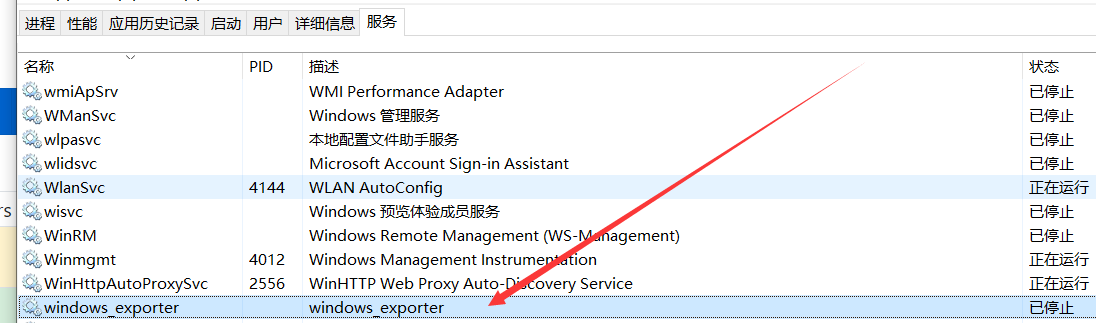
稍等片刻,Promethues将告警发出去了。
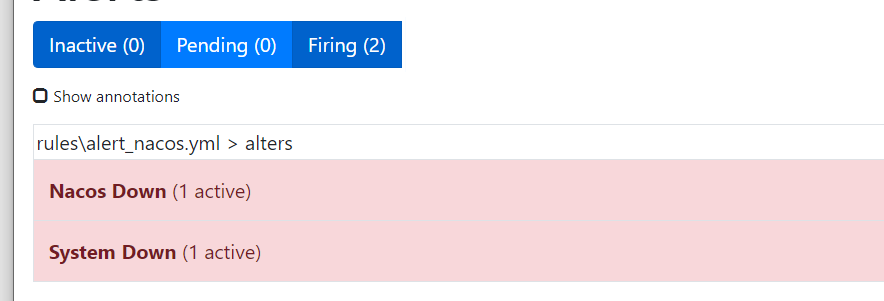
查看Alertmanager控制台,收到了告警,注意他们的标签lable,host表示他们来自于哪台服务器。
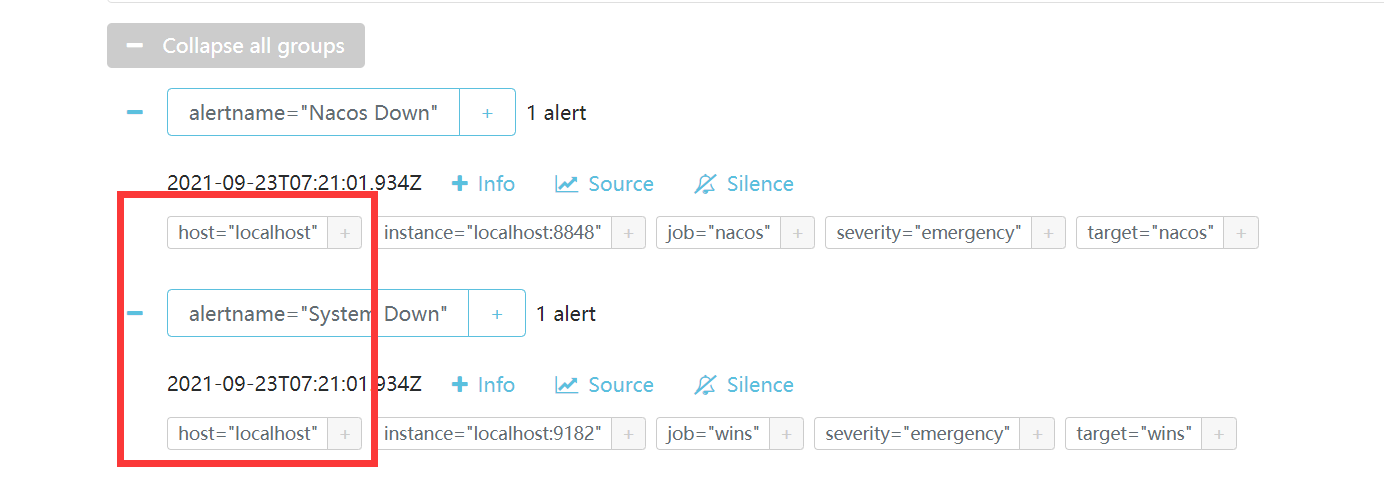
在接入微信通知时,收到了Nacos和System停止运行的信息,在实际开发中,我们应该抑制Nacos挂掉的信息,因为服务器都宕机了,再发送其他服务挂掉的信息,是多余的。
2. 配置抑制规则
在alertmanager.yml添加抑制规则。
inhibit_rules:
- target_matchers:
- job = nacos
source_matchers:
- job = wins
- severity = emergency
equal:
- host
- target_matchers表示目标匹配器,这里表示对job标签为nacos的告警进行抑制
- source_matchers表示来源匹配器,这里表示当发现job标签为wins,并且告警级别为emergency时的告警通知发出,则会对target_matchers中匹配的通知进行抑制。
- equal表示,来源通知和抑制目标通知需要具有相同的host标签,这里表示他们需要来自于同一台服务器
重启Alertmanager,发现只发出了System Down的告警,Nacos相关的已经被抑制了。
静默(Silences)
简介
静默是在给定时间内简单地将警报静默的直接方法。静音是基于匹配器配置的,就像路由树一样。检查传入警报是否与活动静默的所有相等或正则表达式匹配器匹配。如果他们这样做,则不会发送该警报的通知。
案例演示
静默是在 Alertmanager 的 Web 界面中配置的。
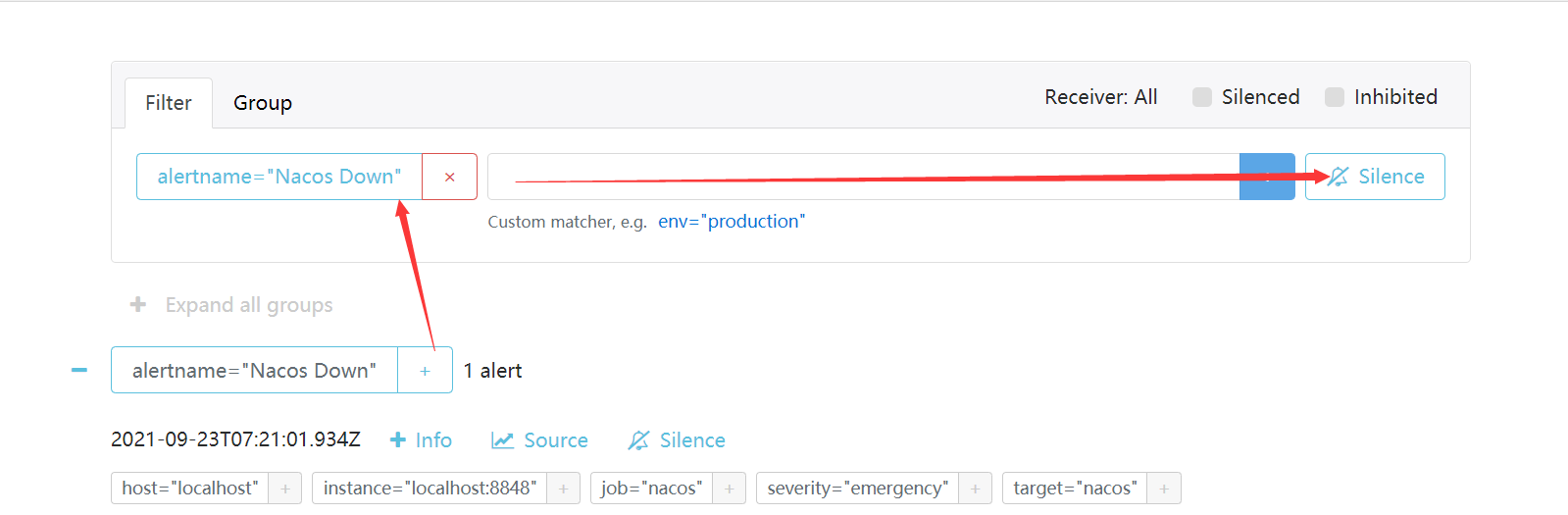
可以在页面上,添加静默时间和匹配器,直接打开Alertmanager 控制台,直接点击告警信息的+号,就会自动添加匹配器。
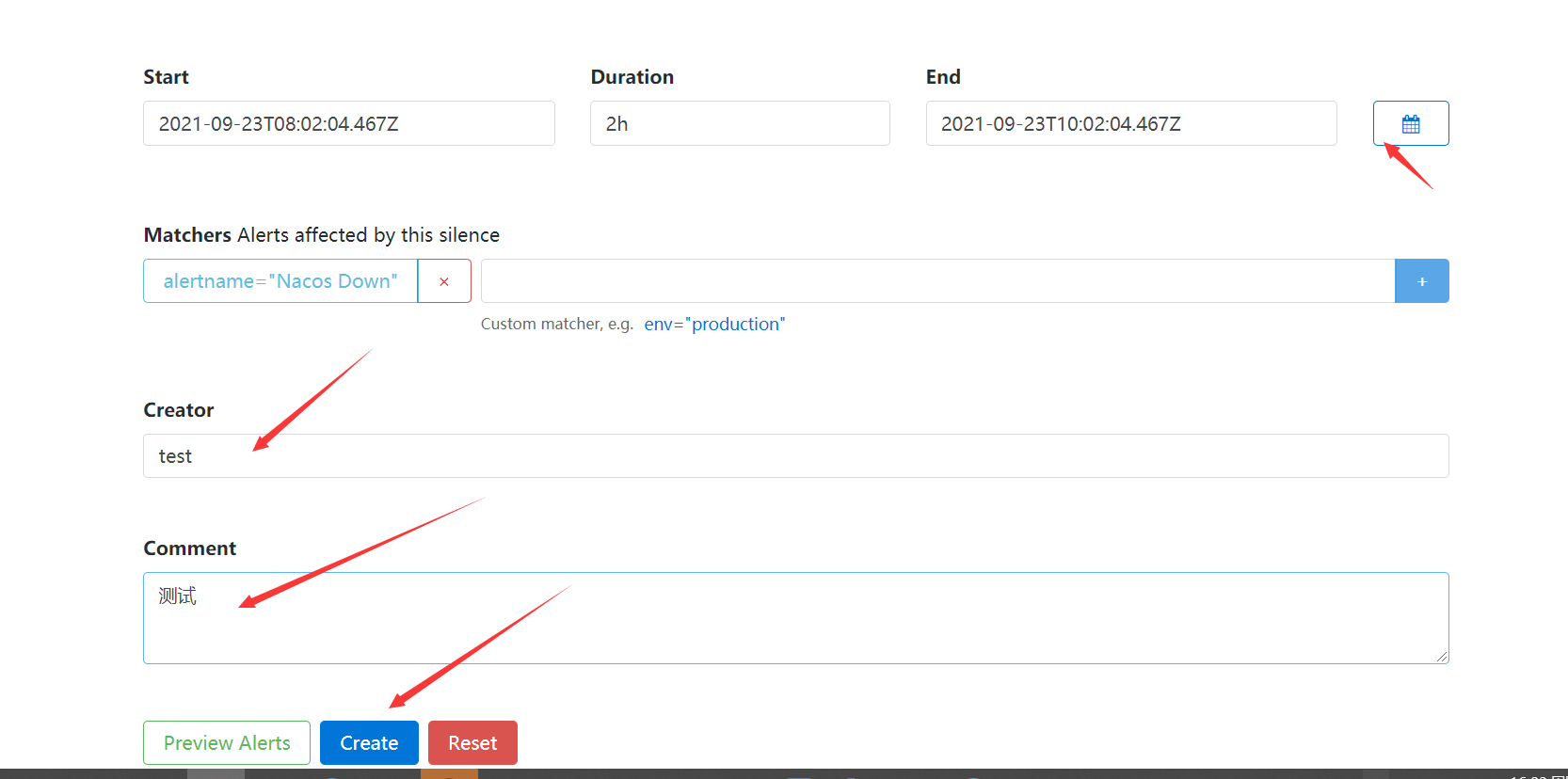
这里选择时间,填写创建者和说明,然后点击Create创建。
然后点击Silences菜单,就能看到添加的静默规则了,
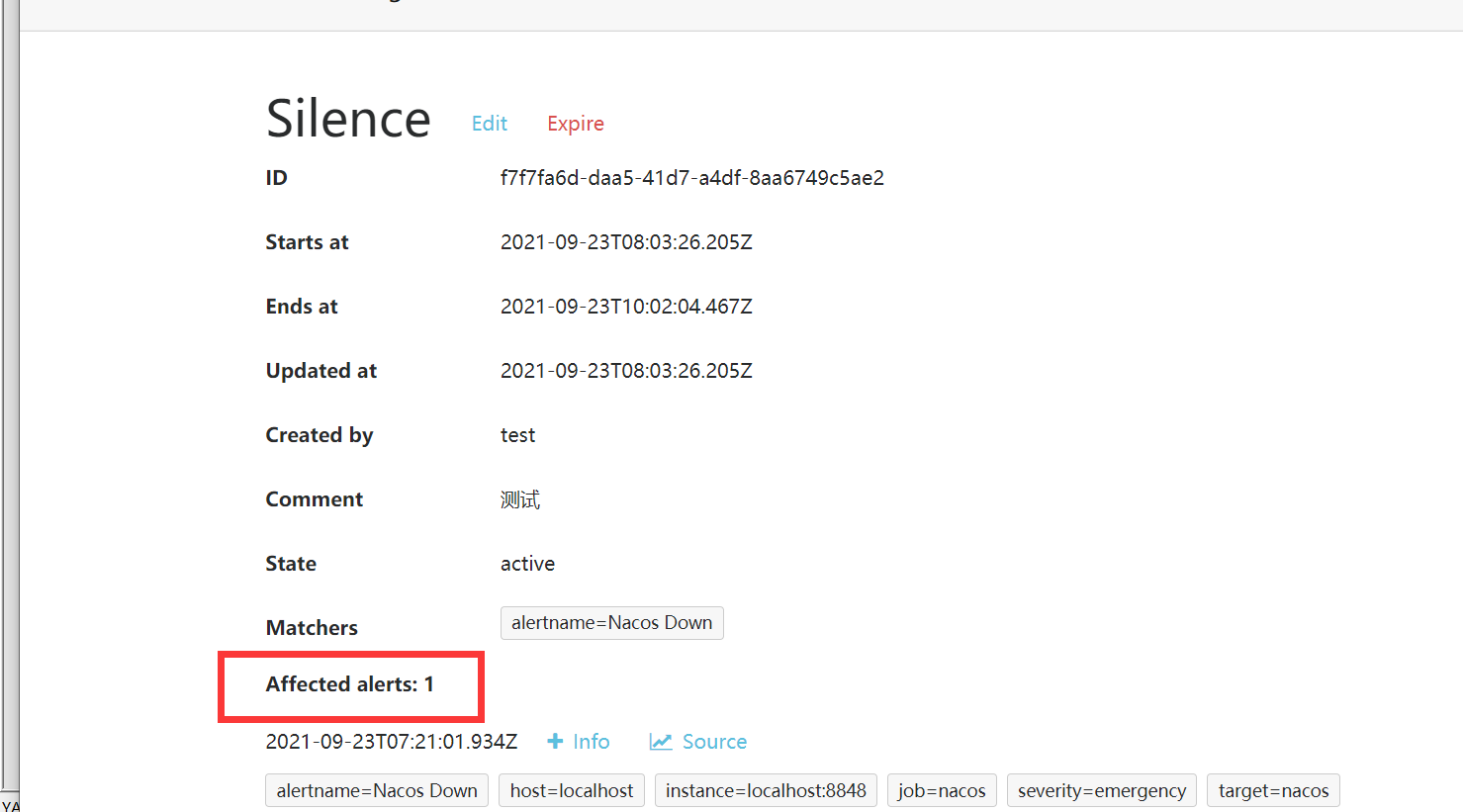
点击View,还能看到当前规则的详情,以及当前已经静默了多少条告警通知。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: