文章目录
- 前言
- 一、基数排序(桶排序)介绍
- 二、基数排序基本思想
- 三、图文解释
-
- 3.1 第 1 次排序
- 3.2 第 2 次排序
- 3.3 第 3 次排序
- 3.4 结果
- 四、代码实现
- 五、基数排序说明
前言
基数排序,属于桶排序的一种,是一种典型的空间换取时间的 稳定式排序。
一、基数排序(桶排序)介绍
1、 基数排序(radixsort)属于**“分配式排序”(distributionsort),又称“桶子法”(bucketsort)或binsort,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用;
2、 基数排序法是属于稳定性的排序,基数排序法的是效率高的稳定性排序法;
3、 基数排序(RadixSort)是桶排序的扩展**;
4、 基数排序是1887年赫尔曼·何乐礼发明的它是这样实现的:将整数按位数切割成不同的数字,然后按每个位数分别比较;
二、基数排序基本思想
1、 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零;
2、 然后,从最低位开始,依次进行一次排序;
3、 这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列;
4、 这样说明,比较难理解,下面我们看一个图文解释,理解基数排序的步骤;
三、图文解释
将数组{53, 3, 542, 748, 14, 214} 使用基数排序, 进行升序排序。
数组的初始状态 array = {53, 3, 542, 748, 14, 214}
3.1 第 1 次排序
- 第1轮排序规则:
1、 将**每个元素的个位数取出,然后看这个数应该放在哪个对应的桶**(一个一维数组);
2、 按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组);
- 排序结果:
数组的第1轮排序结果 array = {542, 53, 3, 14, 214, 748}

3.2 第 2 次排序
- 第2轮排序规则:
(1)将每个元素的十位数取出,然后看这个数应该放在哪个对应的桶(一个一维数组)
(2) 按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组) - 排序结果:
数组的第2轮排序结果 array = {3, 14, 214, 542, 748, 53}
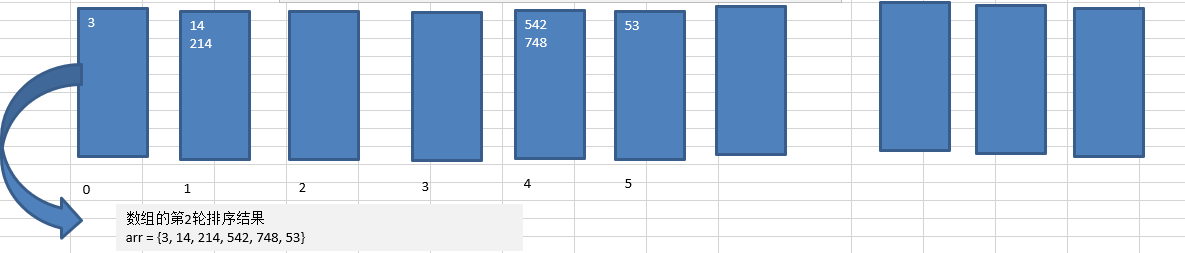
3.3 第 3 次排序
- 第3轮排序规则:
(1) 将每个元素百位数取出,然后看这个数应该放在哪个对应的桶(一个一维数组)
(2) 按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组) - 排序结果:
数组的第3轮排序结果 array = {3, 14, 53, 214, 542, 748}
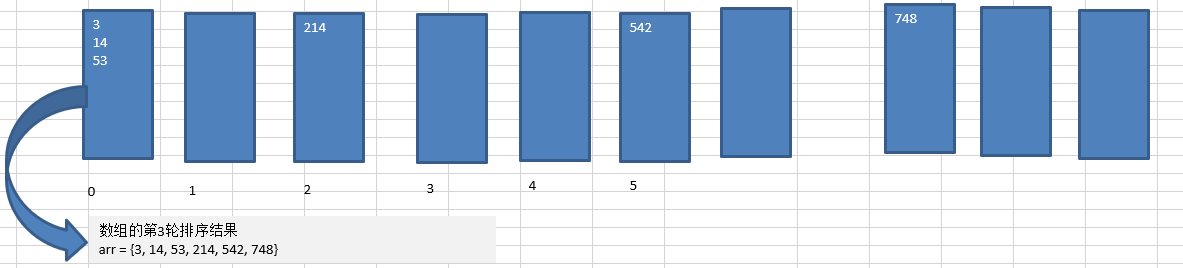
3.4 结果
到了这里,是最终的结果。array = {3, 14, 53, 214, 542, 748} ,
所以,排序几次,需要找到最大数的是几位数。
四、代码实现
1、 deductionRadixSort(int[]array);为学习推导的过程;
2、 radixSort(int[]array);据下面的推导过程,我们得到的最终的基数排序代码;
3、 testTime();测试速度的方法;相当之快,这也正是空间换取时间的原因所在,;
8万数据: 134ms, 80万数据: 269ms , 800万数据:1s 左右 。
当为8000万数据时,会报错:java.lang.OutOfMemoryError: Java heap space,内存溢出错误,因为 80000000 * 11(数组) *4(一个int 4个字节) /1024(k) /1024(m)/1024(g) = 3.3G ,会用到 3.3G内存,所以会内存溢出
package com.feng.ch09_sort;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
/*
* 基数排序(稳定式排序)
* 是空间换时间的经典算法
*
* 速度: 这也正是 空间换取时间的原因所在
* 相当之快:8万数据: 134ms, 80万数据: 269ms , 800万数据:1s 左右 ,
* 当为8000万数据时,会报错:java.lang.OutOfMemoryError: Java heap space,内存溢出错误,
* 因为 80000000 * 11(数组) *4(一个int 4个字节) /1024(k) /1024(m)/1024(g) = 3.3G ,会用到 3.3G内存,所以会内存溢出
* */
public class S7_RadixSort {
public static void main(String[] args) {
int array[] = {
53, 3, 542, 748, 14, 214};
System.out.println("初始数组:");
System.out.println(Arrays.toString(array));
// deductionRadixSort(array); // 测试推导方法
radixSort(array); // 测试推导后 合成的方法
System.out.println();
System.out.println("排序后的数组:");
System.out.println(Arrays.toString(array));
// 测试 80000 个数据排序 所用的时间
System.out.println();
System.out.println("测试 8000000 个数据 采用基数排序 所用的时间:");
testTime(); // 8万数据: 134ms, 80万数据: 269ms , 800万数据:1s 左右 , 8000万数据:
}
/*
* 测试一下 归并排序的速度, 给 80000 个数据,测试一下
* */
public static void testTime() {
// 创建一个 80000个的随机的数组
int array2[] = new int[8000000];
for (int i = 0; i < 8000000; i++) {
array2[i] = (int) (Math.random() * 8000000); // 生成一个[ 0, 8000000] 数
}
// System.out.println(Arrays.toString(array2)); // 不在打印,耗费时间太长
long start = System.currentTimeMillis(); //返回以毫秒为单位的当前时间
System.out.println("long start:" + start);
Date date = new Date(start); // 上面的也可以不要,但是我想测试
System.out.println("date:" + date);
SimpleDateFormat format = new SimpleDateFormat("yyyy-mm-dd HH:mm:ss");
System.out.println("排序前的时间是=" + format.format(date));
radixSort(array2);
System.out.println();
long end = System.currentTimeMillis();
Date date2 = new Date(end); // 上面的也可以不要,但是我想测试
System.out.println("排序后的时间是=" + format.format(date2));
System.out.println("共耗时" + (end - start) + "毫秒");
System.out.println("毫秒转成秒为:" + ((end - start) / 1000) + "秒");
}
/*
* 根据下面的推导过程,我们可以得到最终的基数排序代码
* */
public static void radixSort(int[] array) {
//1、得到数组中最大的数的位数
int max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i] > max) {
max = array[i];
}
}
//2、得到最大数是几位数
int maxLength = (max + "").length();
/*
* 定义一个二维数组,表示 10 个桶,每个桶就是一个一维数组
* 说明
* 1、二维数组包含 10 个一维数组
* 2、为了防止在放入数的时候,数据溢出,则每个一维数组(桶),大小定位 array.length
* 3、很明显,基数排序是使用空间换时间的经典算法
* */
int[][] bucket = new int[10][array.length];
/*
* 为了记录每个桶中,实际存放了多少个数据,我们定义一个一维数组来记录各个桶的每次放入的数据的个数
* 可以这样理解:
* 比如:bucketElementCounts[0] , 记录的就是 bucket[0] 桶的放入数据个数
* */
int[] bucketElementCounts = new int[10];
// 这里使用循环将代码处理
for (int i = 0, n = 1; i < maxLength; i++, n *= 10) {
/*
* 每一轮(针对每个元素的 对应位 进行排序处理)第一次是个位,第二次是十位,第三次是百位,第四次是千位。。。。
* 为了解决这个问题,在上面的 for 循环中,添加了一个 变量 n ,每次 * 10,因为下面需要取出相应的 个位、十位、百位。。。
* 注意点:
* 每轮处理后,需要将每个 bucketElementCounts[i] = 0 !!!
* */
for (int j = 0; j < array.length; j++) {
// 取出每个元素的 个位 的值
int digitOfElement = (array[j] / n) % 10; // =3,第三个桶 //
// 放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = array[j]; // 我觉得第二个 值 有问题
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
int index = 0;
// 遍历每一个桶,并将桶中的每一个数据,放入到原数组
for (int k = 0; k < bucket.length; k++) {
// 或者为:k < bucketElementCounts.length bucket.length 都为 10
// 如果桶中有数据,我们才放到原数据
if (bucketElementCounts[k] != 0) {
// bucket[i] !=0
// 循环该桶,即第 k 个桶(即第K 个数组中),放入 ;bucketElementCounts[k]: 为桶的几个数据
for (int j = 0; j < bucketElementCounts[k]; j++) {
// bucket[i].length 是桶的长度,但是这里应该为 桶里数据的个数
// 取出元素放入到 array
array[index] = bucket[k][j];
index++;
}
}
// 第 i+1 轮处理后,需要将每个 bucketElementCounts[i] = 0 !!!
bucketElementCounts[k] = 0;
}
// System.out.println("第 " + (i + 1) + " 轮,对" + n + "位数的排序处理 array = " + Arrays.toString(array)); //
}
}
/*
* 基数排序
* 使用逐步推导的方式
* */
public static void deductionRadixSort(int[] array) {
/*
* 定义一个二维数组,表示 10 个桶,每个桶就是一个一维数组
* 说明
* 1、二维数组包含 10 个一维数组
* 2、为了防止在放入数的时候,数据溢出,则每个一维数组(桶),大小定位 array.length
* 3、很明显,基数排序是使用空间换时间的经典算法
* */
int[][] bucket = new int[10][array.length];
/*
* 为了记录每个桶中,实际存放了多少个数据,我们定义一个一维数组来记录各个桶的每次放入的数据的个数
* 可以这样理解:
* 比如:bucketElementCounts[0] , 记录的就是 bucket[0] 桶的放入数据个数
* */
int[] bucketElementCounts = new int[10];
/*
* 第 1 轮(针对每个元素的个位进行排序处理)
* 注意点:
* 第 1 轮处理后,需要将每个 bucketElementCounts[i] = 0 !!!
* */
for (int j = 0; j < array.length; j++) {
// 取出每个元素的 个位 的值
int digitOfElement = (array[j] / 1) % 10; // =3,第三个桶 //
// 放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = array[j]; // 我觉得第二个 值 有问题
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
int index = 0;
// 遍历每一个桶,并将桶中的每一个数据,放入到原数组
for (int k = 0; k < bucket.length; k++) {
// 或者为:k < bucketElementCounts.length bucket.length 都为 10
// 如果桶中有数据,我们才放到原数据
if (bucketElementCounts[k] != 0) {
// bucket[i] !=0
// 循环该桶,即第 k 个桶(即第K 个数组中),放入 ;bucketElementCounts[k]: 为桶的几个数据
for (int j = 0; j < bucketElementCounts[k]; j++) {
// bucket[i].length 是桶的长度,但是这里应该为 桶里数据的个数
// 取出元素放入到 array
array[index] = bucket[k][j];
index++;
}
}
// 第 1 轮处理后,需要将每个 bucketElementCounts[i] = 0 !!!
bucketElementCounts[k] = 0;
}
System.out.println("第 1 轮,对个位数的排序处理 array = " + Arrays.toString(array)); //[542, 53, 3, 14, 214, 748]
/*
* 第 2 轮(针对每个元素的个位进行排序处理)
* 注意点:
* 取出每个元素的 十位 的值:int digitOfElement = (array[j]/10) % 10
* */
for (int j = 0; j < array.length; j++) {
// 取出每个元素的 十位 的值
int digitOfElement = (array[j] / 10) % 10; // =3,第三个桶 //
// 放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = array[j]; // 我觉得第二个 值 有问题
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
index = 0;
// 遍历每一个桶,并将桶中的每一个数据,放入到原数组
for (int k = 0; k < bucket.length; k++) {
// 或者为:k < bucketElementCounts.length bucket.length 都为 10
// 如果桶中有数据,我们才放到原数据
if (bucketElementCounts[k] != 0) {
// bucket[i] !=0
// 循环该桶,即第 k 个桶(即第K 个数组中),放入 ;bucketElementCounts[k]: 为桶的几个数据
for (int j = 0; j < bucketElementCounts[k]; j++) {
// bucket[i].length 是桶的长度,但是这里应该为 桶里数据的个数
// 取出元素放入到 array
array[index] = bucket[k][j];
index++;
}
}
// 第 2 轮处理后,需要将每个 bucketElementCounts[i] = 0 !!!
bucketElementCounts[k] = 0;
}
System.out.println("第 2 轮,对十位数的排序处理 array = " + Arrays.toString(array)); // [3, 14, 214, 542, 748, 53]
/*
* 第 3 轮(针对每个元素的个位进行排序处理)
* 注意点:
* 取出每个元素的 百位 的值:int digitOfElement = (array[j]/100) % 10
* */
for (int j = 0; j < array.length; j++) {
// 取出每个元素的 百位 的值
int digitOfElement = (array[j] / 100) % 10; // =3,第三个桶 //
// 放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = array[j]; // 我觉得第二个 值 有问题
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
index = 0;
// 遍历每一个桶,并将桶中的每一个数据,放入到原数组
for (int k = 0; k < bucket.length; k++) {
// 或者为:k < bucketElementCounts.length bucket.length 都为 10
// 如果桶中有数据,我们才放到原数据
if (bucketElementCounts[k] != 0) {
// bucket[i] !=0
// 循环该桶,即第 k 个桶(即第K 个数组中),放入 ;bucketElementCounts[k]: 为桶的几个数据
for (int j = 0; j < bucketElementCounts[k]; j++) {
// bucket[i].length 是桶的长度,但是这里应该为 桶里数据的个数
// 取出元素放入到 array
array[index] = bucket[k][j];
index++;
}
}
// 第 3 轮处理后,需要将每个 bucketElementCounts[i] = 0 !!!
bucketElementCounts[k] = 0;
}
System.out.println("第 3 轮,对百位数的排序处理 array = " + Arrays.toString(array)); // [3, 14, 214, 542, 748, 53]
}
}
五、基数排序说明
1、 基数排序是对传统桶排序的扩展,速度很快.;
2、 基数排序是经典的空间换时间的方式,占用内存很大,当对海量数据排序时,容易造成OutOfMemoryError;
3、 基数排序时稳定的[注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的];
4、 有负数的数组,我们不用基数排序来进行排序,如果要支持负数,参考:https://code.i-harness.com/zh-CN/q/e98fa9;
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: